

Bayesian vs Frequentist — and the winner is!
A post for both technical and non-technical folks

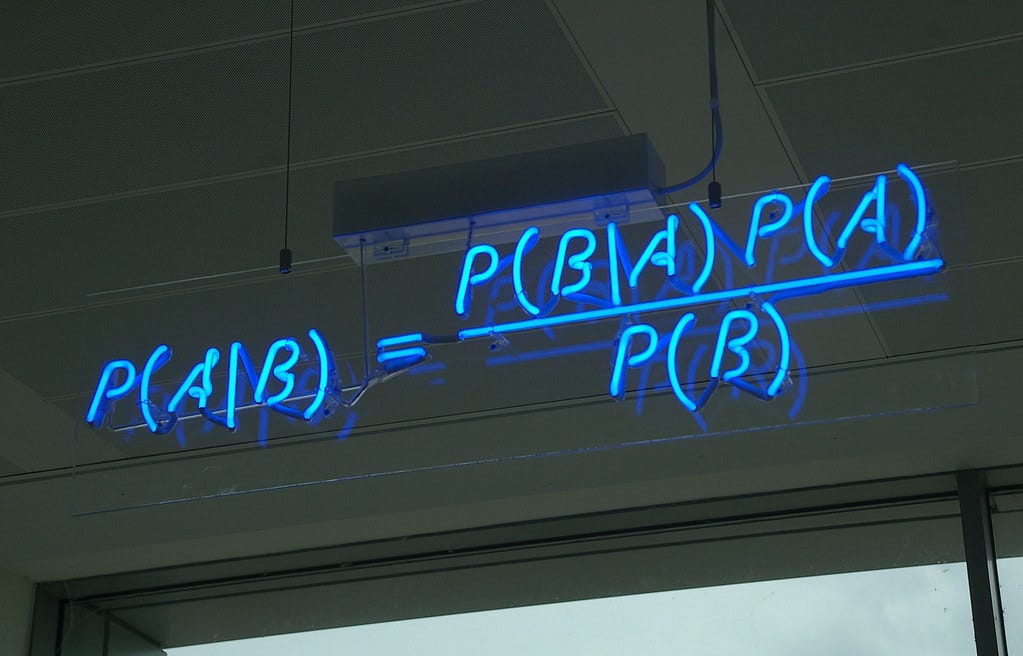
OK, maybe there aren’t any winners — but the debate continues. In this post, I’m not rehashing the same technical arguments. Instead, I’m offering a business-focused, non-technical perspective on the Bayesian vs Frequentist conversation.
This was originally posted on Linkedin but I ran out of characters. This is a cleaned up version of that post with my full thoughts.
The Frequentist Comfort Zone
Having grown up with Frequentist statistics, I know how it works, when to use it, and crucially, its limitations.
I can explain it clearly to non-mathematical people using practical examples relevant to their field. I can also dive deep into the technical details, confidently use online tools to analyse data, and, if needed, code formulas myself in Google Sheets, Excel, or R.
Beyond that, I understand how to interpret results, spot nuances, and question an experiment’s validity without blindly trusting outcomes.
Working in tech for 14 years has given me a deep understanding of organisations, customer needs, and financial models. This allows me to quickly cut through the stats and connect the results to the business objectives for the purposes of rapid decision making. None of this is a brag, it’s simply to say that I understand my discipline at both a theoretical and a practical level and apply it in a way that helps businesses make sense of the world.
The Bayesian Barrier
I don’t feel like I can say the same about my knowledge of Bayesian Statistics, and I’m certainly not starting a debate about the merits of one over the other. I couldn’t care less, although I actually do feel like the future of online experimentation is going to be built on Bayesian maths by smart Bayesian practitioners (like Ryan Lucht, Tyler Buffington and Demetri Pananos Ph.D — you should follow them).
However, after reading a lot of their posts (and countless others), and this is no criticism to any of them, whilst I feel more informed (Bayesian pun intended) about Bayesian Stats, I still don’t feel like it’s accessible to me, let alone the everyday non-mathematical person who leads experimentation at their company. I worry they’ll misuse Bayesian Stats: falling into traps like uninformed priors, wrong beta distributions, or relying on correlative models over informative ones. The tools they’ll use risk mirroring the same pitfalls we see with Frequentist methods, just under a different label.
Bridging the Gap
Many posts dive straight into technical detail — so much Python code! — using dense academic language. That’s understandable, the authors are brilliant people. Don’t get me wrong, I’m not here defending statistical ignorance, but if I’m at the business end of the organisation, I don’t really care about all that. What I want to know is:
How do I use Bayesian Statistics without needing a PhD in stats?
What practical, business-focused examples show me its power? (Demetri’s expected loss example is brilliant, by the way.)
And how can experts make it easier for people like me to run tests confidently, without needing them involved in every single experiment
Frequentist tools have been better packaged for business use — think calculators, dashboards, clear p-values — whereas Bayesian tools often assume statistical fluency.
So, Who Wins?
Whether you’re Bayesian or Frequentist, the same truth applies: if the literature and tools don’t bridge beyond stats and code, decision-makers won’t be able to use them effectively. That disconnect will persist — unless the really smart people either step into business-facing roles or work harder to close the gap.
That’s ultimately why I spent so much time upfront talking about my own background. It’s not to brag, but to highlight a missing piece in the Bayesian experimentation space. The technical foundations are rock solid. The maths is beautiful. But what’s often missing is the bridge — the person who can take those powerful concepts and translate them into something that’s accessible, actionable, and embedded in the day-to-day decisions businesses need to make… and maybe even allow them to self-serve it.
In other words, the Bayesian community doesn’t just need more brilliant statisticians; it needs more people who can build the full end-to-end experience. People who understand both sides — technical rigour and business reality — and can connect the two. I took responsibility to do that myself from a Frequentist stand point, but I don’t know if I have it in me to learn Bayesian stats in the same amount of detail… there’s simply too much good stuff on Netflix.
Because if we don’t build that bridge, the disconnect will persist, no matter how good the maths is.
References: